-
Persistent Object Systems
-
Rob Kremer, University of Calgary
Abstract
This paper surveys the wide range of possible persistent object
systems, from relatively simple object I/O to sophisticated OODBMS systems.
The fundamental requirements of persistent object systems include rich
persistent data models, seamlessness, and reasonably high performance.
However, more sophisticated systems will support evolution of instances
and classes, object sharing, distributed objects, platform independent
objects, concurrency control, flexible transactions, and access control.
Persistent systems can be classified over several dimensions such as object
model used, navigation vs queries, storage type, transaction support, etc.
A detailed look at the simplest persistence implementation (object I/O)
is presented, along with suggestions on how this simple framework could
be extended to support some of the more advanced features.
Introduction
Object persistence is a rather large topic, mostly because it is not extremely
well defined. This is not very surprising because the need for object persistence
springs from the object-oriented programming paradigm, and there exists
no firm, agreed-upon definition of object-oriented programming either.
There is some consensus that object-oriented model means abstraction, encapsulation,
modularity and inheritance hierarchy [Booch 91], but there is much disagreement
about whether it also means typing, concurrency, co-routines and persistence.
Similarly, there is some consensus that persistence means rich data modeling
and seamlessness, but there is much disagreement about whether it also
means queries, object sharing, complex transactions, version control, distributed
objects, platform independent objects, and security support. Based on this
last statement alone, there is obviously a tremendous diversity of possible
persistent systems ranging from humble class library support for object
file I/O to all-encompassing multi-language, distributed, platform-independent
OODBMSs with version control, security features, and support for long and
cooperative transactions.
The objective of this paper is to present an overview of persistent
object systems. Some of the persistence requirements for application programmers
are enumerated in section 2. A rough taxonomy of persistent systems is
presented in section 3. Finally, a detailed view of simple object I/O systems,
the lowest level of persistent systems, is given in section 4. Borland's
object I/O class library is presented as a concrete example in this last
section.
In this paper, the word "persistence" will be taken to mean the very
general concept of objects somehow living between invocations of a program
or programs. This is taken to mean somewhat more than simple file I/O but
not much more. Therefore, "persistent systems" covers anything from simple
object I/O systems, to the most complex and extended OODBs. The term "OODB"
and "OODBMS" will be taken to mean a persistent system with at least some
form of independent storage management (with the object I/O systems don't
have).
It is not within the scope of this paper to discuss the object-oriented
paradigm in detail, so I will assume the reader has his own opinion about
what "object oriented" means. However, a short discussion defining a few
base terms and how they apply to persistence is in order.
Classes, Types and Shapes
Many object oriented languages, like C++, make no distinction between a
class and its type. However, the distinction is often important to persistent
systems. A type is often referred to as an abstract data type (ADT)
and defines the interface (operators or methods) to the object. Shape
is the internal data representation of the type, exclusive of the methods.
A single type may have several possible shapes. A class, on the
other hand, has type and shape, but its definition also includes the implementation
of the object (actual algorithms for the operators or methods as well as
internal data structures and methods) [Wolf 90, Joseph 91]. Therefore,
there can be more than one class for a single shape or type.

These distinctions are important to persistent systems. For example,
a persistent system might be able to allow both a new version of class
definition, as well as the original version (two different classes), to
operate on the same objects in persistent store, if both classes are of
the same type and shape.
Object Identity
Object identity is intrinsic to object oriented programming, but few programmers
give it much thought. It is obvious that each object has a unique identity,
independent of its value, if only due to the fact that it has an address.
But the concept of identity goes deeper than just an address -- one can
envision an object changing type without changing its identity. Object
identity must be maintained by persistent systems to maintain compatibility
with the languages that they support. If this seems trivial, consider relational
databases: a relation is a set of tuples, and since it is a set, if two
tuples have the same values, they are not distinct entities, so object
identity is not supported.
Software Engineering Requirements
Computer applications are becoming increasingly complex, as computers are
being relied on for tasks that would not have been deemed possible just
a few years ago. Next-generation applications will need far more data storage
support from the underlying systems than before [Joseph 91]. This section
describes both the fundamental requirements needed by simple, standalone
applications; and the optional, more demanding requirements for complex
and corporate-wide applications.
Fundamental Requirements
The minimum needs of persistent systems are listed in this section. These
are the attributes that will be needed by the most humble of persistent
object systems, but are by no means sufficient for large scale applications.
Rich Data Modeling
A persistent object system must serve the needs of the software it is supporting.
The data models in object oriented languages are extremely rich, in that
they support hierarchies of objects, objects containing other objects,
objects referencing other objects, and non-objects such as vectors (themselves
containing arbitrary data types). Traditional databases and file systems
do not allow anywhere near this flexibility, but persistent systems should
support it, at least to some degree.
Seamlessness
Persistent objects should be treated just like transient (non-persistent)
objects. To force the programmer to deal with persistent and transient
objects in two different data modeling paradigms is to invite disaster.
Besides the obvious cognitive load, the programmer may not even be able
to map the complex structures required for sophisticated applications into
the simple models offered by traditional databases. This huge gap between
the rich data models used in object-oriented programming languages and
the simple structures representable in conventional database systems has
been called the "impedance mismatch". The translation from the programming
language's modeling paradigm to the database's modeling paradigm can account
for as much as 30% of the code in an application [Joseph 91]. This, and
the obvious large potential for error in the translation is sufficient
reason to attempt to resolve the impedance mismatch and strive for better
integration of a programming language with the database system.
Performance
Next-generation applications will need sufficient performance from their
persistent systems, not only because the demand of the new applications
is great, but because they will need to navigate persistent object networks
in ways not efficiently supported by conventional databases.
Other Requirements
This section lists attributes that the more ambitious and robust persistent
systems must support. The system that supports only the attributes listed
in the above section is humble indeed.
Support for Evolving Instances and Classes
Object structure is not static, but can be very dynamic as the system evolves.
An object store should be able to store objects that are under development
without loosing reference to them when some programmer alters their schema.
The object store needs some form of version control.
Sharing of Objects among Applications
It is desirable to share objects among various applications, perhaps even
applications written in different languages. This introduces problems of
concurrency control and platform independence.
Distributed Objects
The concept of the distributed object store, like the distributed database,
is clearly of importance. However, a distributed object store is more complex
than a distributed database because objects have operators as well as attributes.
How is one to carry operators (code) among dissimilar systems in a heterogeneous
environment? Furthermore, how is object identity to be maintained when
they migrate from system to system?
Platform Independent Objects
Ideally, objects could be accessible to a variety of languages, and possibly
within a variety of operating systems and machine architectures. This is
no trivial matter. Sharing objects among languages is not easy since languages
tend to differ considerably in data models, inheritance capabilities, message
handling, etc. The situation can be even worse when sharing objects among
different systems since it posses further problems such as code compatibility,
memory models, and system interaction.
Concurrency Control
An object store in any multi-tasking environment must have some sort of
concurrency control to prevent multiple tasks from inadvertently corrupting
the objects by concurrent access. The integrity of the object's identity
is also at issue here. Thus, a multi-access object store must support some
concept of transaction.
Flexible Transactions
The simple lock-and-commit transactions of current database systems are
inadequate for next-generation applications. Various cooperative design
applications, such as cooperative CAD, can require very long transactions
that may not commit for hours, days or weeks [Joseph 91]. Such transactions
may need partial commits or some sort of cooperative locks.
Security
Any sophisticated object store has to contend with the security problem.
No one is going to trust their finely crafted objects to a system that
is going to let just anybody modify or delete them.Other Database Models
Persistent System Taxonomy
It is obvious from the previous discussion of various demands made on persistent
object stores that persistent systems can be categorized along very many
(not necessarily orthogonal) dimensions. The major dimensions of comparison
include the object model, navigation vs queries, storage, transactions,
queries, change management, access control, remote databases, interlanguage
sharing, and user interfaces. More detailed discussions of persistent system
taxonomy can be found in [Joseph 91] and [Kim 90]. Table 1 is an attempt
to summarize the points of comparison, while the rest of this section expands
on the taxonomy.
|
Issue
|
Sub-issue
|
Range
|
|
object model
|
programming language and database integration
|
integrated
|
|
not inegrated
|
|
value oriented vs OODB
|
value oriented
|
|
OODB
|
|
treatment of classes and types
|
class-based
|
|
type-based
|
|
object identity support
|
OIDs directly supported
|
|
Side-by-side name spaces
|
|
entity relationship
|
|
relational queries
|
|
active vs passive objects
|
active
|
|
passive
|
|
navigation vs queries
|
persistent language based
|
extensions
|
|
custom language
|
|
query based
|
supported
|
|
not supported
|
|
indexing
|
class hierarchy
|
single class
|
|
class hierarchy
|
|
nested attribute
|
supported
|
|
not supported
|
|
storage
|
type
|
typeless page servers
|
|
typeless object servers
|
|
class-based object servers
|
|
type-based object servers
|
|
clustering and prefetching
|
supported
|
|
not supported
|
|
transactions
|
nested transactions
|
supported
|
|
not supported
|
|
type specific transactions
|
supported
|
|
not supported
|
|
long and cooperative transactions
|
supported
|
|
not supported
|
|
queries
|
queries
|
supported
|
|
not supported
|
|
predicates
|
class-based (relational)
|
|
type-based (allows methods)
|
|
response sets
|
heterogeneous
|
|
homogeneous
|
|
language conformation
|
|
semantics
|
shallow
|
|
deep
|
|
change management
|
versions
|
not supported
|
|
supported
|
|
configurations
|
not supported
|
|
supported
|
|
transformations
|
not supported
|
|
supported
|
|
access control
|
not supported
|
|
object centered
|
|
OODB centered
|
|
remote databases
|
not supported
|
|
supported
|
|
interlanguage sharing
|
not supported
|
|
data layout
|
|
semantics
|
|
method sharing
|
|
user interfaces
|
not supported
|
|
supported
|
|
implementation
|
class library
|
|
language extension
|
|
custom language
|
Table 1: A summary of points of comparison of persistent systems
Object Model
Object models used by persistent systems vary along several dimensions
including degree of integration of the programming language and database,
value-oriented versus object-orientation, treatment of classes and types,
method of maintaining object identity, and use of active versus passive
object activity.
Integration of Programming Language and Database
Integration of the programming language and database data models is one
of the most salient goals of persistent systems, however different implementations
achieve this goal to varying degrees and from different points of view.
Programs written using conventional databases expend considerable effort
(as much as 30% of code) in converting from the programming language's
data model to the database's, while systems that have totally integrated
the object store with the language have to spend no extra code whatsoever
in the storage and retrieval of data. Most programmers have experienced
the former with C programs trying to store networks of dissimilar objects
on stream files. An example of the latter is the Smalltalk and Lisp environments
where objects can be stored within the environment, and become, essentially,
a part of the executable code. An intermediate example is the case of C++
class libraries that implement persistence by inheritance; programmers
extending persistent classes by inheritance must write custom code to translate
memory to persistent store, while users of the classes get a (relatively)
free ride [Borland 91, Foster 90].
Value Oriented vs OODBs
Value-oriented databases, like the relational model, store relationships
between entities indirectly, by virtue of shared data values. For instance,
the concept of Fred's dog having fleas may be expressed as the tuples (Fred,
Rover) and (Rover, has-fleas). There is no relationship between Fred's
dog and the flea-bitten dog, except by virtue of both having the same name.
This obviously does not have the power needed by the object model, but
extensions of the conventional data model such as the nested relational
model (a relation can have another relation as a tuple member), entity
relationship model, and semantic data models can more easily mimic the
true objects [Joseph 91].
On the other hand, true object-oriented databases reject the more conventional
data models in favour of a true object model. (Although critics note that
the object model isn't a lot different from the earliest databases using
the hierarchical and network models.) While the object model is more to
the point, value-oriented extensions have the advantage of a good deal
of technology behind them, and the possibility of smooth migration from
current systems.
Classes and Types
Many object oriented languages do not recognize the distinction between
class and type, however the distinction is important to object persistence
since an implementation can use type or shape information to materialize
an object from store, but without class, it cannot interact with it. Even
in systems where the object store does not interact with the object, but
leaves that totally up to the programming language, it is still an important
concept since a single type or shape may have application to more than
one class or more than version of the same class.
Object Identity
Object identity must somehow be preserved. The most straightforward way
to do this is simply to directly model the programming language and replace
memory pointers with object identity codes (OIDs). The OIDs must be large
enough to be unique for each element within the object store. Persistent
object references must incur the overhead of a run-time check and a fetch
if the OID references an object that has not yet been brought from memory.
For example, E [Schuh 90] uses indirect pointers though "handles" -- objects
that encapsulate the information about the physical location (disk or memory)
of the object.
A alternate approach is to use the entity relationship model, where
all inter-object references are outside the scope of the object and are
separate objects in their own right. This method is slower because references
are not directly accessible from inside an object.
Another approach is to go with the relational database approach and
force all references to be queries. This does not necessarily rule out
object identity because artificial "uniqueness" fields can be created.
This approach can be very clean in systems that support efficient queries
since there is only one access method, but the expense of calling the query
processor for every single reference could be prohibitive.
Side-by-side name spaces is another approach that is (more or less)
intermediate to queries and OIDs. These implementations support separate
names spaces for transient and persistent objects. Ada PGraphite and C++
Persi [Wolf 90] use the persistent name space to bring objects into working
memory, where the transient name space is used. EC++ [Sequeira 91] and
Arjuna [Dixon 89] use the persistent name space for all persistent references.
Active vs Passive Objects
Passive object storage most resembles conventional database storage in
that objects can only receive and send messages once they have been materialized
in the program's working memory, where the object is under sole control
of the program. Active object storage allows (or enforces) messages to
be sent to the objects while they remain in the object store. Therefore,
the object store has complete control of the interaction of the program
with the persistent objects. This can be very powerful in enforcing very
fine-grained security, and in allowing "object views". Only the higher-end
systems (type-based object servers) such as Arjuna [Dixon 89] support active
objects, while low-end implantations are stuck with passive objects.
Navigation vs Queries
Navigation is searching on the basis of following pointers through
a network of objects. Querying is searching by making queries
(boolean expressions) on records in a set (a class in this case). Queries
spring from traditional database technology. Programming languages traditionally
perform search on their (non-persistent) data structures by navigation.
Therefore, persistent language based OODBs naturally perform navigational
search (owning to their programming language heritage), while query language
based OODBs naturally perform query search (owing to their database heritage).
Persistent language based OODBs (Navigation)
Persistent language based OODBs can be class libraries for existing OO
languages, extensions of OO languages, or OO languages designed solely
to accommodate persistence, but their overriding goal is to eliminate the
"impedance mismatch" between program language and database. They reference
persistent objects in the object store transparently in exactly the same
way as they reference dynamic objects -- usually by references internal
to other objects. All program data structures (including vectors, lists
and sets) are generally supported as first class objects to maintain the
smooth integration of persistent data with non-persistent. These languages
have a hard time supporting common database features such as concurrency
control, locking, and version control. It is unclear how persistent language
based OODBs could support multiple languages.
An example of an extension language is E [Schuh 90], an extension of
C++ which introduces an new storage class persistent, and new db
primitive types. [Atwood 90] is a comparison of a persistent C++ extension
(OQL) and a C++ class library implementation. OQL is also interesting in
that it is a C++ language extension that also supports queries.
Query-language OODBs
Query language OODBs don't worry about the "impedance mismatch" problem,
and instead borrow from the mature relational database model. As a result,
they support only sets as first class objects. The concept of pointers
to persistent objects is lost in favour of confining all persistent references
to queries, although these queries can be in the form of "path names" to
allow for more specific reference beyond the standard query result sets.
Of course, the object model is supported, since objects in the database
can (almost) directly reference other objects, and queries are often generalized
to include methods invocation. It is clear that query language based OODBs,
in contrast to persistent language based OODBs, could support multiple
languages.
Indexing
There is more than one type of hierarchy in any object oriented system,
the major ones being the inheritance (isa) hierarchy and the composition
(part-of) hierarchy. The same distinction occurs in OODBs.
Class Hierarchy
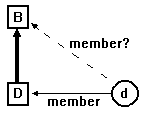
In class (is-a) hierarchy indexing, classes are viewed as sets, just
as a domain is a set in the relational database model. A query is a search
through all objects (members) in a particular class (set). There arises
here a problem: in light of inheritance, what are we to define as members
of a class? If class D inherits from class B, then is object d (an instance
of D) also a "member" of class B, since it "is-a" B and contains all data
members and methods of B? An OODB that considers only direct instances
of the target class is said to have single-class indexing; an OODB
that considers all instances (direct or instances of all derived classes)
is said to have class-hierarchy indexing [Kim 90]. OODBs that support
queries must support one of these indexing capabilities.
Nested Attribute
In nested attribute (part-of) indexing, queries can be made on the bases
of attributes of objects contained in the target objects. This is obviously
useful for a large class of queries, but can be an expensive operation.
This capability may or may not be supported by an OODB.
Storage
Typeless Page Servers
Typeless page servers pay no attention to object semantics or object structure;
they deal only with pages of virtual memory, mapping persistent memory
into the working space of a program. This sounds like a simple and fast
scheme, but it has problems. Pointers must be offset to the page boundary
instead of real virtual memory pointers. This can cause performance problems
because all pointers need an extra level of translation. This is not a
problem in languages like Smalltalk where all pointers are OIDs anyway.
Further problems arise with multiple access and concurrency control. Examples
of this storage model are Exodus [DeWitt 86] and ObjectStore [Atwood 90].
Typeless Object Servers
There is not much difference between typeless page servers and typeless
object servers in that they both have no concept of an object's semantics.
The typeless object servers, however store the objects according to natural
object boundaries, and so can grant finer grained concurrency control.
Examples of this storage model are Zeitgeist [Ford 88], Mneme [Moss 88]
and ObServer [Reiss 86].
Class-based Object Servers
Class-based object servers can handle queries, since they are "aware" of
object attribute structure, but cannot execute methods of their objects.
Many class-based object servers are no more than relational databases for
objects. Thus, they have all the limitations of the relational model: no
direct reference and inability to store non-class objects like arrays and
vectors. Class-based object servers can be further divided into horizontal
partitioning servers (objects derived from inheritance are flattened
to store all attributes in a tuple) and vertical partitioning servers
(each class's non-inheritied attributes form a tuple and objects derived
from inheritance are spread over several tuples in their lineage). Examples
of class-based servers are Postgres [Stonebraker 86] and Iris [Fishman
87].
Type-based Object Servers
Type-based object servers are fully "aware" of object semantics: they comprehend
both attributes and methods. Type-based servers can handle both complex
queries (involving methods) and inter-object navigation. Type-based object
servers are often just extensions of any of the other three types: A software
layer is added to act on an object once the more basic server materializes
it in memory. Examples of type-based servers are Orion [Banerjee 87] and
O2 [Deux 90]. An interesting intermediate form between type based and class
based servers is SOS-C++ [Shapiro 89] where objects can carry around "code
objects".
Clustering and prefetching
Any of the storage methods can be further divided according to optimization
methods (or lack thereof). Clustering is the arranging of objects into
larger blocks to optimize access. Prefetching is usually in the form of
predictive caching.
Transactions
Shared databases of any kind must allow for some form of concurrency control
or transaction management in order to maintain consistency. Since OODBs
must support sophisticated next-generation applications such as multi-user
CAD, they must pay particular attention to this problem and handle it in
a very general manner. The least sophisticated persistent systems will
ignore the problem altogether, while the most powerful OODBs will have
to account for very long transactions and cooperative transactions.
Nested Transactions
The concept of nested transactions is that parent transactions can have
sub-transactions. An OODB that actually handles messages will have to embody
this concept since method invocation will have to be handled as a transaction
too. Method invocation necessarily implies the possibility of resulting
method invocations which are also transactions -- nested transactions.
Arjuna [Dixon 89] supports nested transactions.
Type Specific Transactions
In conventional database technologies, concurrency control is limited to
knowledge about the read/write semantics on the objects. However, OODBs
open up other possibilities. If the semantics of the object are known there
is no reason to necessarily restrict concurrent transactions to a single
atom object. For example, there is no reason to refuse concurrent enqueueing
and dequeueing operations on a queue.
Long and Cooperative Transactions
Cooperative CAD and similar application raise the possibility of very long
transactions where the design may not have a commit for very long periods
(even months!). This is not very feasible with conventional lock-and-commit
transaction mechanisms. Various mechanisms have been proposed such as checkpointing
(traditional), nested transactions, piggy-back transactions (a transaction
splits and each passes its lock to the next), and cooperative transactions
(many readers may observe during a writer's update [Joseph 91].
Queries
Not all persistent systems support queries, but even the ones that don't
will allow the programmer to build query support into the class library.
We are more interested here in the ones that support query directly. Obviously,
the typeless page server and typeless object server storage models cannot
support queries, since they know nothing about the semantics of the objects
what so ever.
Predicates
Persistent systems vary according to types and power of queries they support.
OODBs based on the class-based object server storage model can support
relational query types, since they are based on the relational model. Thus
they can support queries based on primitive attributes of an object only.
On the other hand, OODBs based on the type-based object server model can
support much more sophisticated queries. Since they have more semantic
knowledge about the objects, they can use methods in their queries as well.
Method calling within queries can get complicated, so some of these OODBs
may choose to make restrictions to method calls such as "no side effects",
etc.
Response Sets
Persistent systems differ in the query response sets they can offer. Since
inheritance exists in OO systems, a query could legitimately return a heterogeneous
response set. For example, a query requesting all pet animals in a certain
household could return a set containing both a cat class instance and a
dog class instance (both inheriting from class animal). Postgres [Stonebraker
86] offers heterogeneous response sets while others do not.
Semantics
Semantic problems arise in OO queries. For instance, inheritance is often
used in two different ways: as an is-a relationship, or simply for code
sharing. So, if class Android inherits from class Person, how do you answer
a query about all Persons with red hair? One would not expect to see an
Android in the reponse set. However, one would expect to see ComputerScientists
(inherits from Person) in the response set. Somehow, the OODB should know
about such things. Likewise, the part-of hierarchy suffers from similar
problems.
Change Management
Change management in OO systems is a very complex issue and is a topic
in itself. I know of no persistent system that fully supports it, and most
ignore it completely. Change management applies to individual objects and
also to classes and types. Change types include versions (trees
or lattices of update histories to objects, classes or types), configurations
(evolving object composition or class hierarchy structure), and transformations
(operations applied to the object, class or type). To illustrate, when
a class or type is modified, its version changes; if it changes its inheritance
structure, its configuration changes; when any modification is made to
the type or shape, it may perform a transformation to change (either overwrite
or version) all the objects that are direct or indirect instances of the
class.
Access Control
Sophisticated OODBs require some sort of security measures to prevent unauthorized
changes or deletions. OODBs have possibilities over conventional DBs because
objects have the potential to control their own access.
Remote Databases
Persistent systems differ in their support of remote (possibly heterogeneous)
databases. The object orientation of the persistent systems will make it
easier for them to transparently support access to remote, heterogeneous
systems. Arjuna [Dixon 89] is primarily designed around remote (but not
heterogeneous) access.
Interlanguage Sharing
Persistent language-based persistent systems are obviously not good for
interlanguage sharing, however there is no reason for query language-based
OODBs not to support multiple languages. Issues in interlanguage sharing
include data layout differences between the languages (such as word alignment
issues), semantic differences between languages (such as statically vs
dynamically sized arrays), and the question of how to handle arbitrary
methods in multiple languages (do you have to code every method in every
language?).
User Interfaces
OODBs may or may not have user interfaces. Interfaces are needed to browse
data and class/type hierarchies. The same browsers may be used within the
programming language environment as well. Since OODBs will make it easier
to store multimedia information (images, video and audio), the OODB may
act as a central repository for this information, and as such it will need
multimedia editors and other tools.
Implementation
The simplest implementations confine themselves to the syntax and semantics
of an existing programming language, and implement persistence through
inheritance in a class library. Ada PGraphite, C++ Persi [Wolf 90], ObjectWindows
[Borland 91], and TCL Object Input/Output [Foster 90] are all examples
of this. More commonly, persistence is implemented as a language extension,
such as a new storage class for C++ (E [Schuh 90], SOS [Shapiro 89]) or
other extensions (OQL [Atwood 90]). Still other implementations involve
completely new languages.
Low-end (class library based) Persistence
The rest of this paper is dedicated to low-end persistence -- persistence
at the humble object I/O end of the spectrum. My reasons for doing this
are twofold: Low-end persistence is a reasonable way to illustrate the
complexity of persistent systems without writing a book. And I feel that
low-end persistence is a practical way to go for many applications, and
is still a viable area with ample territory for research.
It is my contention that, for practical purposes, a developer using
OO technology today should endeavor to aim at low-end, class library-based
persistence models. See [Atwood 90] for the opposite opinion, [Wolf 90]
for a supporting opinion. The lowest persistent model is little more than
object I/O. Object I/O involves persistent objects belonging (by inheritance)
to a persistent class which contains constructors, destructors, and methods
which handle the object I/O in a reasonably transparent manner. This does
not mean that all objects inheriting from a persistent class are necessarily
persistent, but all such objects have the potential to be persistent.
It is generally accepted that persistence should be orthogonal to type
[Wolf 90].
This may sound very conservative, but I believe that the OO paradigm
makes even simple object I/O a very powerful tool, since objects can be
made to "instantiate themselves".
Why aim so low?
Lack of standards
There are currently no agreed-upon standards for OODBs, furthermore, there
is no consensus on what a OODB is. In the absence of such agreement, if
the point of using any OODB is to share data with other applications, it
would be foolhardy to go charging off investing large amounts of time,
money and effort pursuing a complex, all-encompassing OODB platform when
it is extremely unlikely that any other application is likely to adopt
the same OODB platform. If you are not going to share data with any other
applications, or just "known" applications, there isn't much point in pursuing
the holy Grail either. Only if one is part of a very expensive research
program, directed at just this technology, should one pursue such a high
goal.
High cost of DB approach
Even when appropriate third part OODB products are available, they should
be used with caution. Will the target sites have licence to use that particular
OODB product? Would they be able to afford the licence? Even if licensing
costs are low, a site may reject installation of the OODB on the grounds
of already having "too many" DBs. These problems have to be considered
even for research programs where empirical testing at target sites is required,
or where the research is targeted to have practical application in the
near future.
Programming "in the small"
There has been much talk of "programming in the large", but let's not ignore
"in the small" applications. This is where most applications are, after
all. And with server architectures, more and more problems are going to
fall to the "small" applications. It undoubtedly makes sense for "small"
application to use the low-end persistence technology. Obviously, use of
low end persistence is not appropriate for "programming in the large" where
we consider large corporate-wide databases that demand high security, sharing,
and multi-language access. These "large" applications may be able to spend
the effort and risk to take advantage of sophisticated OODBs, but it may
be wiser to use OO technology to encapsulate conventional DB technology
within the objects themselves -- inheriting the persistence through the
class hierarchy -- essentially using the low-end persistent systems approach.
Language version problems
Persistent systems that involve language extensions (beyond that of a simple
pre-processor) tend to have problems whenever the base language is upgraded.
It can take considerable time for the extension vendor to catch up to the
base language vendor. In the meantime, the user either is left with an
incompatible system or is forced to hold off using the new base language
features. EC++ users weren't happy about being tied to C++ 1.2 when C++
2.0 was available [Sequeera 91].
Object I/O
Object I/O is one of the simplest forms of persistence. It usually is not
supported by the language itself, but by the class library. It does not
directly support sharing of an sort, queries, transaction management, change
management, security, remote access, or user interfaces. Object I/O is
not an OODB implementation because there is no true storage management.
Storage management is left solely to the programmer. But, because of the
encapsulation afforded by the OO paradigm, most details of storage management
are left to the objects themselves, so this is not as big a problem as
one would imagine. The simplest models use stream files as a storage medium,
however, there is no reason why other DB facilities might not form the
underlying storage medium of an object I/O facility. It should be noted
that stream I/O, especially the C++ stream I/O style, can also serve as
a method to communicate objects over character-based lines, and so form
a practical bases for object migration between systems.
In the following discussion, I will use C++ terminology, since the case
example (to follow) will use C++.
Object I/O is not quite as simple as the preceding paragraph makes it
sound. In these implantations, a PERSISTENT base class contains virtual
functions for object input and output to a file. Each persistent class
must inherit from PERSISTENT and override the input (reader) and output
(writer) functions. The writer function is responsible for writing each
data member to a file. The reader function is responsible for exactly the
reverse, reading in the object from a file (in exactly the same
order).
Writer function
The writer function is responsible to write each data member to the file.
We can simplify by just writing all the data members that are unique to
this class and calling the output function of the parent class(es). Writing
out the data members is simply done by writing each data member of primitive
type to the output stream, and calling the output function of each user-defined
class member. However, a problem arises with pointers. We could assume
that a referenced object is merely written to the file as well. But if
the object A references another object B via a pointer, it is possible
that another object C also references the same object, B.
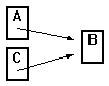
If both objects A and C are stored, the B object would be copied into
the file twice. Now, when the objects are read back A and C would each
reference separate copies of B,
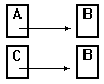
and we have violated the object identity of B, which is not what we
want. To get around this problem, a runtime (memory) output database
must be kept of all object addresses written to the file. When an object
is written to a file, the output database is checked to see if the object
has been written out before; if it has, a reference (object identifier)
is written to the file instead. That way, when the object is read back
the second time, the reader will be able to reference the original object
via the input database (see the next section).
Reader function
The reader function is responsible to read each data member from a file
in exactly the same order as the writer function wrote it. Again,
this is done by reading in all data members introduced in this class, and
then calling the reader functions of parent class(es). Primitive types
are simply read from the file, and the reader functions of any class members
are called. Similar to the output database mentioned above, an input
database is kept of all objects read in. This database associates the object
identifiers (created when the objects were written) of all the objects
read in with the objects' current address. Now, when an object identifier
is found in the input stream (put there when a duplicate object reference
was detected on output), the object identifier is referenced in the database
to obtain its memory address.
Note that the entire writer-and-reader scheme is totally dependent on
the order of reading exactly duplicating the order of writing. As long
as the writer and reader functions are all coded correctly, the order will
always be correct, no matter how complex the object reference graph.
Storage Management
As stated above, in object I/O persistence, all storage management is left
up to the application programmer. But this is not a serious matter, since
for many classes of programs, there are small numbers of storage units,
where a storage unit is a self-contained object graph. For example, a word
processor may have units of default settings, a current document, and maybe
an address database. The point is that programs generally do not operate
on huge numbers of independent objects -- they are usually highly interconnected
by virtue of being in sets, lists, arrays, or otherwise referenced by one
another. The programmer may choose to store each of these units in separate
files, or to store them all in the same file in a specific order
(and to retrieve them in the same order). Separate files have certain advantages
for sharing, since in the word processor mentioned above, if the address
database is a separate file, then that same file may be used (non-concurrently)
by other applications. An even better method is to encapsulate the address
database in a server program (agent object) who controls it and could enforce
safe, concurrent access, authorization, and even change management.
Case Example: Borland's Streamable Objects in C++
Borland C++ offers an object I/O implementation with their ObjectWindows
class library [Borland 91].
All persistent classes must have the class TStreamable as one
of their direct or indirect base classes. TStreamable defines the
pure virtual member functions read(), write(), and streamableName(),
which all subclasses must redefine. Furthermore, a streamable class should
overload the << and >> (stream I/O operators). Optionally,
the streamable class can have a build() member function and a special
builder constructor. See table 2 for an explanation of all these functions.
All of these (except streamableName()) operate on a special stream
library, whose root is class pstream (see fig. 1), that parallels
the standard stream library.
|
Function
|
Explanation
|
virtual void* write(opstream)
(protected)
|
Responsible to write the object out to the opstream. This
is usually done by first calling the write() member functions of
any direct superclasses, then writing out all data members introduced by
the class. Writing out data members is done by calling their <<
operators on the opstream. |
virtual void* read(ipstream)
(protected)
|
Responsible to read the object from the ipstream in exactly
the same order as the write() member function wrote it. This is
usually done by first calling the read() member functions of any
direct superclasses, then reading in all data members introduced by the
class. Reading in data members is done by calling their >> operators
on the ipstream. |
virtual const char*
streamableName(void)
(private)
|
Returns the name of the class as a character string for
the use of the stream manager. |
static TStreamable* build(void)
(public)
|
Note that build() is a static member function; it
is global to the class, not an object, and can be called without
reference to a particular object: "<class-name>::build()". build()
is used to return an "empty" object -- space is allocated, but nothing
is initialized and the constructors are not called for any of the contained
objects. This is done by simply returning an instance constructed with
the builder constructor. Thus, build is always defined as:
<class-name>* <class-name>::build()
{return new <class-name>(streamableInit);}
|
builder constructor
(protected)
|
This is a special constructor which always has the format:
<class-name>(StreamableInit) :
<base-class-name>(...) [,...] {};
which has the effect of calling all the parent constructors, but does not
initialize any of the data members. StreamableInit is a special
constant used to select this special constructor. This signals the compiler
not to initialize the data members. |
operator >> (ipstream, <class>)
operator >> (ipstream, <class>*)
operator << (opstream, <classs>)
operator << (opstream, <class>*)
|
These are the operators that the user of the class actually
uses when performing object I/O. They are always defined as:
ipstream operator>>(ipstream is, <class-name> cl)
{return is >> (TStreamable)cl; }
ipstream operator >> (ipstream is, <class-name>* cl)
{return is >> (void*)cl; }
opstream operator<<(opstream os, <class-name> cl)
{return os << (TStreamable)cl; }
opstream operator<<(opstream os, <class-name>* cl)
{return os << (TStreamable*)cl; }
|
Table 2: Member functions and overloaded operators used in a streamable
class definition.
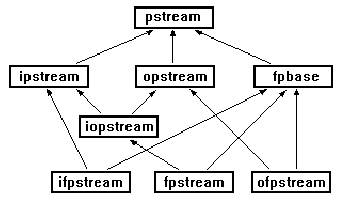 fig. 1: pstream library
fig. 1: pstream library
It should be obvious, from the access control specifiers (public, protected,
and private) in table 2, that the member functions are not normally used
by the application programmer. The application programmer only uses the
<< and >> operators. Thus, the application programmer
need only open a stream (usually done in the constructor) and then write
and read the objects using << and >>.
Multiple references
This is all clean and simple, but for the problem of multiple references
to the same object. As stated in the previous section, if more than one
reference to the same object is written to the stream, a naive implementation
would end up reading back the references as pointing to distinct objects.
To get around this problem, a database (a list in memory) is kept of all
objects written to and read from a stream. The information in the database
is accumulated during the execution of << ipstream and >>
opstream operators. The output database (<<) associates memory
address with object identifier (OID). The input database (>>) associates
OID with memory address. OIDs are generated during output to the stream.
Reading in unallocated objects: build()
There is also the possibility of reading in a pointer to an object. The
object is on the stream, but the object we are materializing is only a
pointer to it: there is no memory pre-allocated to the data members or
the virtual function table. The job of allocating the memory and initializing
the virtual function table is the domain of the class's static build()
member function (see table 2). The only problem is how to find the address
of the build function, given that we know only the name of the class (which
we can get from the stream -- see "object I/O algorithms"). The solution
is a database associating class names to their build function addresses.
But where is this database to come from? Borland's solution is to ask the
class author to declare a static object of type TStreamableClass
in the class's .CPP file. TStreamableClass's constructor "registers"
the class by putting it's name and build() member function address in the
database.
TStreamableClass Reg<class-name>("<class-name>",
<class-name>::build,
__DELTA(<class-name>);
where __DELTA is a macro that computes the offset of TStreamable
within the class. There is a further problem in that if this declaration
is off in an object library somewhere, it's constructor will never be called.
The solution is to have the class user include a macro, __link(Reg<class-name>),
that forces the constructor to be called. The macro is not intuitive, but
it does the job:
#define __link(s) extern TStreamableClass s; \
static struct fLink {fLink *f; TStreamableClass *t;} \
force##s={(fLink*)&force##s, (TStreamableClass*)&s};
I will leave it to the reader to convince himself that this really does
force a call on the TStreamableClass constructor.
Object I/O algorithms
The steps to object output (<<) are:
-
The output data base is checked to see if this address has been written
before, if it has then the OID is written to the stream, and we are done.
-
The classname (from the streamableInit() virtual member function)
is written to the stream.
-
The OID is generated, and written to the stream.
-
The object is output to the stream by calling the object's virtual write()
member function.
-
Save the object address and OID in the output database.
The steps to object input (>>) are:
-
Look at the next element on the stream. If it is an OID, then the object
must already have been read and we need only look up the OID in the input
database to determine the memory address. We return a reference to this
address and we are done.
-
Otherwise, read in the class name, and construct the object if necessary
(see "Reading in unallocated objects").
-
Read in the OID from the stream.
-
The object is read from the stream by calling the object's virtual read()
member function.
-
Save the OID and object address in the input database.
Using object I/O
From the user of the persistent class's point of view, the only requirements
for saving an object are:
-
make the class known to the stream manager: __link(RegMyClass);
-
open the ofpstream: ofpstream os("myfile.dat");
-
write the object: os << myobject;
To read the object back, the user need only:
-
make the class known to the stream manager: __link(RegMyClass);
-
open the ifpstream: ifpstream is("myfile.dat");
-
declare the object appropriately:
myClass myObject(StreamableInit); // an instance
myClass *myObject; // a pointer
-
read the object: is >> myObject;
The author of the persistent class needs to do considerable more work:
-
Make the class a subclass of TStreamable
-
Override the virtual member functions read(), write(), streamableName(),
and, optionally, static build().
-
Create a special constructor: <class-name>(StreamableInit);
-
Declare a static instance of TStreamableClass: TStreamableClass Reg<class-name>("<class-name>",<class-name>::build,__DELTA(<class-name>));
Possible Extensions to Object I/O
Simple object I/O covers the fundamental requirements for persistence,
but perhaps it could be extended to cover some of the other requirements
such as change management, sharing, distributed objects, concurrency control,
transactions management and access control while still maintaining the
basic simplicity and low cost of implementation as a class library. The
idea here is to avoid special languages, language extensions or pre-processors.
Performance
On the whole object I/O is very fast, due to its simplicity. However, there
is a particularly severe bottleneck: the reader, writer, and class/type
database accesses used during the I/O can be as source of inefficiency.
One should pay careful attention to the efficiency of these operations.
A simple sorted list may not be appropriate! In fact, Borland's version
implements the databases with a dynamic hash table.
Auto Read and Write (Transparent Persistence)
It is not hard to imagine implementing a class in which persistence is
almost completely transparent to the application programmer. One could
simply have the class "know" of the file in which its objects are stored.
An object of that class would access an appropriate instance in its constructor,
and update the stored copy in its destructor. Problems with this implementation
would be:
In what file would we store the objects?
-
Do all the objects of this type go into the same file? What about instances
of subclasses?
-
How would we differentiate this instance from all the others in the file?
If there are several small instances occurring within different scopes,
how does each persistent object's constructor "know" where in the file
to find its location in the file? There are several possible schemes. Which
is the easiest for an application programmer to use?
-
What do we do about objects referencing different object types? The example
implementation would fail if each class uses a separate stream because
OIDs are local to streams.
Loading Partial Objects
One problem with the object I/O gathering networks of objects is: what
do you do if the network is too large to fit into available memory? The
obvious solution is to more objects into memory in a "lazy" manner (defer
until referenced). There are several possible schemes to handle lazy migration,
including the use of handles in pointer indirection [Shuh 90]. They all
involve much more sophisticated persistent object naming conventions.
Persistent Name Space
If more than one object network is to be stored in a single file, and the
objects cannot read in a consistent order, how are we to find the individual
objects? Basic object stream I/O doesn't help us much. A persistent object
naming convention and an efficient method of scanning for named objects
is required. The addition of a "name server" to the basic object I/O scheme
is a possibility.
Schema Evolution
A persistent system introduces increased problems with new software releases.
If the class (shape) of persistent objects is changed between releases,
then the users' persistent data is incompatible with the program. How are
we to deal with this? Should all classes also know how to read older versions?
(Considerable overhead.) Can we automatically generate a program to convert
old object bases? (No run-time overhead, but potentially painful for users.)
Servers
Special purpose programs (processes) could be built to act as persistent
object servers in almost any operating system environment -- all using
nothing but object I/O capabilities. Even on the lowly IBM PC, these could
be build as MSWindows DLLs. Each server could serve all the objects of
a particular class with great flexibility. The basic stream object I/O
capability for C++'s general streams allow interprocess object transfer
even to remote sites over character-based communication lines. The application
programmer could be insulated from even being aware of the existence of
the server, as all this could be encapsulated within the class library;
he/she would only need use a persistent class, the constructors and destructors
would take care of the rest. Such a system could, in theory, offer all
the benefits of the most sophisticated OODB, without compromising the program's
data model. It might even support queries. It could support change management,
sharing, distributed objects, concurrency control, transactions management
and access control. It would be a sophisticated OODB. But now, does
it have all the difficulties and expense of a big OODB? Hmmm...
Conclusion
I have presented the basic concepts for persistent systems, examined the
software engineering requirements, classified persistent systems in several
dimensions, and, finally, presented one of the simplest forms of persistence
(namely object I/O) in a fair bit of detail. It is my hope that this last
detailed example will give the reader an appreciation for the relative
complexity of the higher forms of persistence. Finally, I have suggested
a few lines of further work on gracefully extending the class library based
object I/O model into higher forms of persistent systems, without the need
for new or extended languages
References
[Atkinson 91] Atkinson, Malcolm. "A Vision of Persistent Systems." Extended
Abstract for Invited Paper. Deductive and Object-Oriented Databases,
Second International Conference, DOOD '91. Delobel, C; Kifer, M.; Masunaga,
Y. (Eds.), Lecture Notes in Computer Science Series #566, Springer-Verlag
Berlin Heidelberg 1991.
[Atwood 91] Atwood, Thomas. "Two Approaches to Adding Persistence to
C++." In Implementing Persistent Object Bases: Principles and Practice,
the Fourth International Workshop on Persistent Object Systems, September
23-27, 1990, Morgan Kaufmann Publishers Inc, 1991. pp. 369-383.
[Banerjee 87] Banerjee, J. et al. "Data model issues for object-oriented
application." ACM Transactions on Office Information Systems, vol.
5, pp.3-26, January, 1987.
[Booch 91] Booch, G. Object oriented design with applications.
Benjamin/Cummings, Redwood City, Calif., 1991
[Borland 91] Borland International Inc. ObjectWindows for C++: User's
Guide. Scotts Valley, CA., 1991.
[Duex 90] Duex, O. et al. "The story of O2." IEEE Transactions on
Knowledge Data Engineering, vol,2, pp.91-108, March 1990.
[DeWitt 86] DeWitt, D.; Carey, M. "Object and file management in the
EXODUS extensible database system." In Proceedings of the International
Conference on Very Large Data Bases, 1986, pp.91-100.
[Dixon 89] Dixon, G.N.; Parrington, G.D.; Shrivastava, S.K.; Wheater,
S.M. "The Treatment of Persistent Objects in Arjuna." The Computer Journal,
vol 32, no. 4, 1989. pp.323-332.
[Fishman 87] Fishman, D. et al. "Iris: An object-oriented database management
system." ACM Transactions on Office Information Systems, vol.5,
pp.48-69, January, 1987.
[Ford 88] Ford, S. et al. "Zeitgeist: Database support for object-oriented
programming." In Proceedings of the Second International Workshop on
Object-Oriented Database Systems., 1988, pp.23-42.
[Foster 90] Foster, R.K. "TCL Object Input/Output." Journal of the
Symantec Programming Languages Association, Fall 1990.
[Joseph 91] Joseph, John V., Thatte, Satish M., Thompson, Craig W.,
Wells, David L. "Object-Oriented Databases: Design and Implementation."
Proceedings of the IEEE, vol 79, no. 1, January 1991. pp 42-63.
[Kim 90] Kim, Won. "Object-Oriented Databases: Definition and Research
Directions." IEEE Transactions on Knowledge and Data Engineering,
vol. 2, no. 3, September 1990. pp 327-341.
[Moss 88] Moss, J.E.; Sinofsky, S. "Managing persistent data with Mneme:
Designing a reliable, shared object interface." in Proceedings of the
Second International Workshop on Object-Oriented Database Systems,
1988, pp.298-316.
[Reiss 86] Reiss, S.; Skarra, A.; Zdonik, S. "An object server for an
object-oriented database systems." In 1986 International Workshop on
Object-Oriented Database Systems, 1986, pp.196-205.
[Schuh 90] Schuh, Dan; Carey, Michael; Dewitt, David. "Persistence in
E Revisited -- Implementation Experiences." In Implementing Persistent
Object Bases: Principles and Practice, the Fourth International Workshop
on Persistent Object Systems, September 23-27, 1990, Morgan Kaufmann
Publishers Inc, 1991. pp. 345-359.
[Sequeira 91] Sequeira, Manuel; Marques, Jose Alves. "Can C++ be Used
for Programming Distributed and Persistent Objects?." In Proceedings
of the International Workshop on Object-Orientation in Operating Systems,
Ed. Cabrern, L.F.; Ruso, U.; Shapiro, M. Palo Alto, Ca, Oct 17-18, 1991.
pp.173-176.
[Shapiro 89] Shapiro, M.; Gautron, P.; Morsseri, L. "Persistence and
Migration for C++ Objects." In ECOOP 89: Proceedings of the Third Conference
on Object-Oriented Programming, 1989, Shephen Cook, Ed.
[Stonebraker 86] Stonebraker, M.; Rowe, L. "The design of Postgres."
In Proceedings of the 1986 ACM SIGMOD International Conference on Management
of Data, 1986, pp.340-355.
[Stroustrup 91] Stroustrup B. The C++ Programming Language (second
edition). Addison-Westley, Reading, Mass., 1991.
[Wolf 91] Wolf, Alexander L. "An Initial Look at Abstraction Mechanisms
and Persistence." In Implementing Persistent Object Bases: Principles
and Practice, the Fourth International Workshop on Persistent Object Systems,
September 23-27, 1990, Morgan Kaufmann Publishers Inc, 1991. pp. 360-368.
Rob Kremer, Knowledge
Sciences Institute, University of
Calgary, February, 1992.